Part Identification Using AI: Methodology and Approach for High Accuracy | Inspektlabs
It is vital to understand how part identification functions since AI damage inspections would not be possible without it. As with any other technology, car part identification is bound to improve over time.

Car part identification is an indispensable component of car damage detection. In this blog, we will discuss the fundamentals of car part identification. We will cover the two practical approaches, object detection, and semantic segmentation. We will delve into the different models that enable part identification by analyzing how they function. Finally, we will discuss the metrics we use to judge the models.
Introduction
Part identification is one of the most crucial tasks in AI damage detection. Identifying the part, whether hood, bumper, windshield, etc., is necessary for accurately locating the damage on the car, determining the car's angle and pose, and other processing tasks.
Thus, it becomes critical to identify the car parts in an image or video frame. This task becomes challenging since there are many frames and pictures, and running heavy models to identify the car parts is time-consuming.
Building a system or model that accurately determines the car part and responds quickly is essential for an efficient flow for vehicle damage detection using AI.
There are two methods of part identification:
● Object detection
● Semantic Segmentation
These approaches have unique advanced algorithms rooted in deep learning. These algorithms accurately predict the object they are trained on upon testing unseen test data.
1. Part Identification Through Object Detection
Object detection is the task of determining the object in an image through localization. The algorithm marks the location of an object using an identifying box and even the class it belongs to if there are multiple objects in an image.
Let us consider an example. In the image below, the algorithm detected multiple classes as there are numerous parts on the car body, like the front door, bumper, window glass, etc.

Since time is a factor, we will use lighter models to detect parts for real-time detection. One such model we will use is SSD with lighter backbones like Mobilenet.
The main feature of object detection is that it marks up objects in rectangular boxes. As we can see from the above test image model predictions, there are bounding boxes for each part with its class name and confidence value. The model predicts each part of the car accurately.
Despite the detection model's fair predictions, this approach has shortcomings. The first is that it predicts the box, not the actual boundary of the part. For example, in the above image, we can see that two or more bounding boxes overlap at the corner or side of a car part.
Hence, the central pixels on the image of the bounding box belong to the correct class, while the corners and boundaries are ambiguous. Second, there may be multiple bounding boxes for a single part.
We will have to select a mechanism to choose one. For a single part, it's evident that the box with the highest confidence value is to be selected. However, this process becomes complicated when two class parts are in the neighborhood with multiple bounding boxes.
So for our problem, we will have to devise an algorithm that accurately predicts the part with each pixel to the class it belongs to with unique part class membership. While doing that, the algorithm must circumvent the ambiguity of multiple boxes at corners or sides.
2. Part Identification Through Semantic Segmentation
The semantic segmentation method comes to our rescue with the requirements we had to identify the car parts. This method assigns a unique class to each image pixel and for multiple instances of the same object. Various algorithms come under this method, like Unet, U2Net, FCN, ParseNet, etc.
We will use the Unet algorithm for our task because it gives good predictions once trained on data. The algorithm is also straightforward to implement. The architecture of Unet is illustrated below.
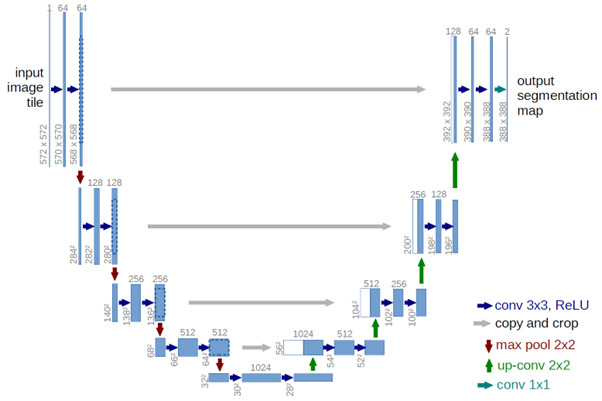
Unet consists of two parts: the encoder and the decoder. The encoder part encodes the raw image into high-level features after a series of convolutions and max-pooling.
At the end of the encoder part, it has several feature maps, ranging from 512 to 2048 or even greater from the 3-channel or grayscale image. Although we have high-level feature maps for segmentation, we have lost the localization details during sub-sampling.
In the decoder part, we will upsample the feature maps, i.e., increase the resolution of feature maps, e.g., from 4x4 to 8x8. We will use high-level features and feature maps from the encoder to get accurate segmentation maps to retrieve the localization information.
This information together creates a feature map. The subsequent upsampling and combination of the feature maps from the encoder part gives us an accurate segmentation map. This has been tested well and gives better results. This approach is applicable in many use cases, like for medical purposes or satellite imagery.
At the decoding stage, the upsampled feature maps are concatenated with the encoder feature maps having the same resolution. After applying a convolution operation, it gives the features maps with high-level information and localization details. This process is repeated till the last phase of the segmentation decoder stage.
The architecture described above is that of the Vanilla Unet. This model performs well but takes time to predict the contents in the image. This factor can be improved with slight modifications, i.e., the encoder part can be replaced with a backbone of CNN classification architectures.
This backbone can be MobileNet, Resnet, VGG, ResNeXt, etc. Since we need a fast inference network, we will use MobileNetV2 as the backbone to get the high-level features from the raw image.
The architecture of MobileNetV2 consists of the first convolution to the raw image followed by residual bottleneck layers 19 times that form the classification network transforming the raw image to a vector that can be used in classification.
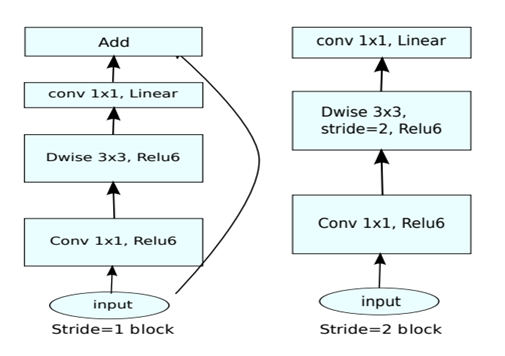
The above diagram shows the bottleneck structure used in the MobilenetV2 network, which, when repeated, forms the network. There are two separate structures based on the stride.
In Unet we will use a pre-trained network trained on a large dataset like ImageNet and use this network to fine-tune the segmentation dataset. This will enable us to fine-tune the network quickly.
Moreover, if the dataset is extensive, we can train the model from scratch with random initialization. The other feature of Unet is that the model can be made strong using data augmentation techniques. These can include brightness-contrast change, cropping, rotation, and other geometric transformations or combinations.
We need data with the image and its corresponding mask or ground truth to train the segmentation model. The mask will contain the mask id or class id of the part it was mapped to.
If N car parts are to be segmented, we will encode each part with its class id starting from 1 and ending at N. The background class will be allotted a class id of 0. The convention can be changed depending on the programmer/engineer. The below pair of raw images with its mask is shown below.



Once training is over, the model can predict unseen data, i.e., test data, to determine how well it performs. Once it shows good predictions, the model will be selected and put to deployment. Below are some results:



Other test results:


Using semantic segmentation, we can identify each part accurately using the Unet model with MobilenetV2 as the backbone. This method is much more efficient in identifying car parts through images than object detection methods.
The efficiency stems from the fact that each pixel belongs to only one. In object detection, on the other hand, because of overlapping boxes, each pixel can belong to multiple part classes. Another benefit is that the detection box can contain the background part which is almost removed in the segmentation model.
KNET
Although Unet does give reasonable predictions, there are cases where the model mis-performs in test cases of car images. It may provide an incorrect mask for highly reflective, glossy cars, the boundary may not be smooth, minor parts may go undetected, or it may deliver a patchy mask or broken mask.
So, there is a need to devise a model largely free from these defects. One such model we can use is Knet.
Knet is a unified framework for semantic Segmentation, instance segmentation, and panoptic Segmentation. The K in Knet stands for kernels, which segments semantic and instance categories through a group of kernels.
Each kernel is responsible for generating a mask, either for instance or stuff class. In the previous architecture, we had static kernels operate on image and feature maps, but this time we have dynamic kernels.
The randomly initialized kernels train upon the targets they seek to predict. Semantic kernels predict semantic categories, while instance kernels predict the instance objects from the image.
This simple combination of semantic and instance kernels allows us to make panoptic segmentation which combines both semantic and instance segmentation to provide richer segmentation results with a better understanding of context.
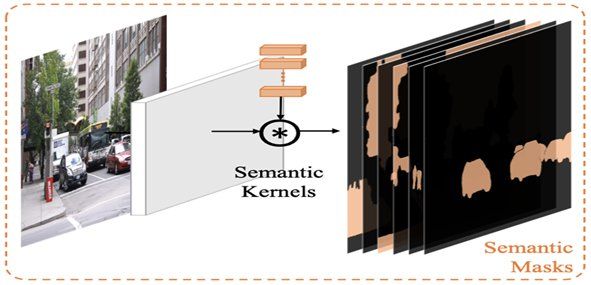
As the figure above shows, the semantic kernels produce the semantic masks. The semantic masks are based on the class of object pixels they belong to. Multiple objects belonging to the same class are allocated a single mask in case of semantic segmentation.
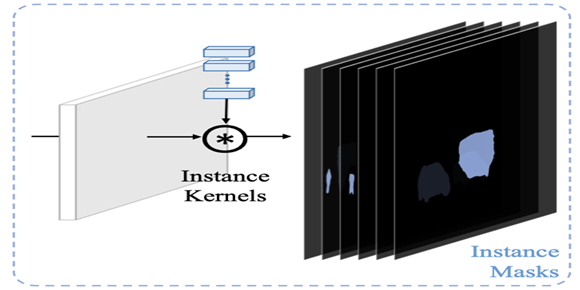
The picture above shows the instance kernels operating on feature maps to produce instance masks. Instance masks make one mask for a single object. Multiple masks are created if there are multiple objects of the same class, which is the essence of instance segmentation.
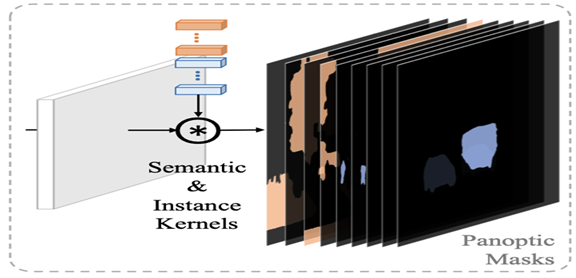
In Knet, we use both semantic and instance kernels to be applied on feature maps to give a group of masks that contain both semantic and instance masks, more likely as panoptic segmentation. Each kernel produces a mask, so combining these kernels is necessary to achieve this.
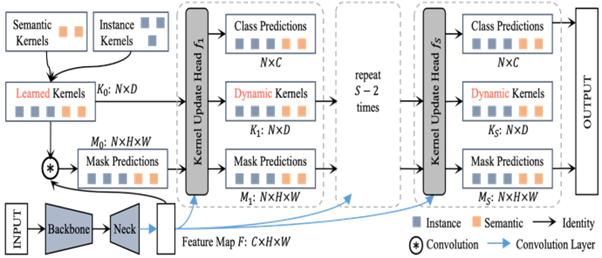
This figure shows the architecture of Knet for segmentation purposes. As illustrated above, they need both instance and semantic kernels that are learned. A backbone takes the raw image and produces a feature map.
Kernels are applied to the feature maps to give mask predictions at the initial stage. The next step is to send them to a set of operations applied repeatedly until it gives the final output. These sets of operations are defined in the dashed block in the figure above.
The Kernel update Head is the main component that defines the dynamic behavior of kernels, which is different from the previous architectures. This differentiation arises because of their static kernels once trained and model weights saved.
The Head takes feature maps, previous block-learned kernels, and mask predictions. After processing, it gives the newly learned kernel dynamically set that, in interaction with the previous mask predictions, gives new mask predictions but with iterative refinement.
This process is repeated till the number of steps is defined after which final masks are predicted.This model will be used in our car parts segmentation to identify each part with better accuracy and fewer defects. Let's compare the Unet results and Knet. In the images below, the results on the left are from Unet; the results on the right are from Knet.




Metrics for Judging the Accuracy of Part Identification
Since we train multiple models either by changing the model/algorithms, its backbone or by modifying the data and its different forms of representation, we need some measure of how accurate our model is and how correctly its predictions are.
When we have several models, we need to compare them and pick the best model based on its performance on test data. For this purpose, metrics come in handy. These metrics are IOU and Dice Score.
IOU score is one of the most used metrics to evaluate the model. It is used in many competitions to compare performances and rank them based on their scores. It is defined as below:
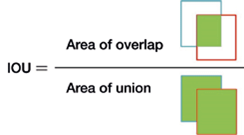
It's the ratio of the area of intersection to the area of union. The two areas considered here are ground truth, i.e., the actual and correct segmentation mask as labeled, and the other is the predicted mask, predicted by the model.
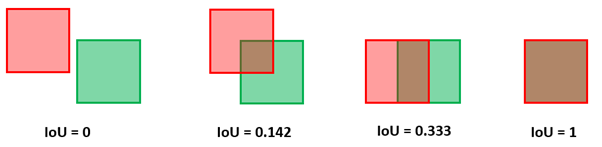
These two areas are used to determine their intersection and union, which finally gives us the IOU value for the given object or class. Its value varies from 0 to 1. If there is no overlap, the score is 0. If there is complete overlap, the score is 1. In every other case, the value lies between 0 and 1.
The below diagram shows different IOU scores for different types of overlap:
We will get multiple IOU scores based on the formula above if there are multiple classes in a single image. The final score can be either the average or weighted average of different classes to reflect the model prediction on the image.
Another metric that can be used is the Dice score. This evaluation method is illustrated below:
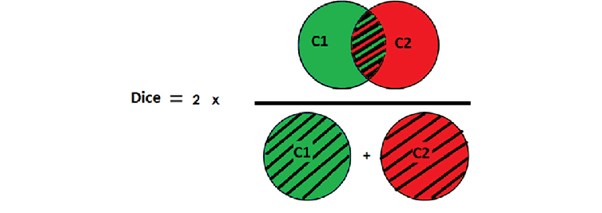
As the diagram clearly shows, the dice score is two times the ratio of intersection area to the sum of areas. Its value also ranges from 0 to 1. Zero signifies no overlap, while 1 denotes a perfect overlap between ground truth and predicted mask.
Conclusion
We now have a comprehensive understanding of how we employ AI for part identification. It is vital to understand how part identification functions since AI damage inspections would not be possible without it. As with any other technology, car part identification is bound to improve over time. The current models Inspektlabs employs offer highly accurate and reliable results.


