AI Car Damage Detection: How it works - Part 2
In this blog, we will run through our existing systems that have been working to train our AI models and the new systems that we have implemented since then. Let’s dive in!

In our previous blog, we discussed the different models Inspektlabs uses to train our AI car damage detection system and how we achieved up to 95% accuracy in our vehicle inspections. But in the fast-moving world of AI, our models need constant evolution.
That’s why we’ve upgraded our training systems to incorporate self-supervised and semi-supervised learning techniques, helping us detect car damage with greater precision and less manual effort.
In this blog, we’ll walk you through the current and emerging AI methods we’re using for vehicle damage detection and explain how our models continue to evolve.
Understanding AI-based vehicle damage detection
Before we get into the details of the models we have been using, let’s first understand the capabilities of AI and the types of damages it can detect.
Types of car damage
AI-based systems like ours focus on physical vehicle damage, which typically falls under three main categories:
- Metal damage - Includes scratches, dents, tears, and structural damage on the metal body panels of the vehicle.


- Glass damage - Refers to cracks, chips, and spider-web fractures on windshields, windows, back glass, headlights, and more.


- Miscellaneous damage - Covers issues like part dislocation, panel gaps, and misalignments that don’t fit strictly under metal or glass damage.


These damage types form the basis of our car damage detection system.
Models behind AI car damage detection
To build a robust vehicle damage detection system, we rely on a hybrid approach that combines:
We have been relying on two main methods to train our AI models. These include -
- Object Detection
Uses deep learning models like YOLO, EfficientDet, and Faster R-CNN to locate and classify car damage in photos. These models excel at identifying multiple types of damage in a single frame.
- Image segmentation
Assigns each pixel in an image a label, helping identify the exact damage area. We use advanced segmentation models such as Vision Transformers for this purpose.
- Ensemble learning
Introducing Self-Supervised Learning
What Is Self-Supervised Learning (SSL)?
Self-supervised learning is a training method where the model learns from unlabeled data by generating its own pretext tasks (like predicting missing parts of an image). It’s been a breakthrough in AI model development, particularly in natural language processing (NLP).
Famous examples include:
- ChatGPT and DeepSeek, which use methods like:
- Causal Language Modeling (CLM) – Predicting the next word in a sentence.
- Masked Language Modeling (MLM) – Predicting missing or hidden words.
However, car damage detection relies on visual data, not text. Let’s see how SSL works in the realm of computer vision.
Self-supervised learning for computer vision
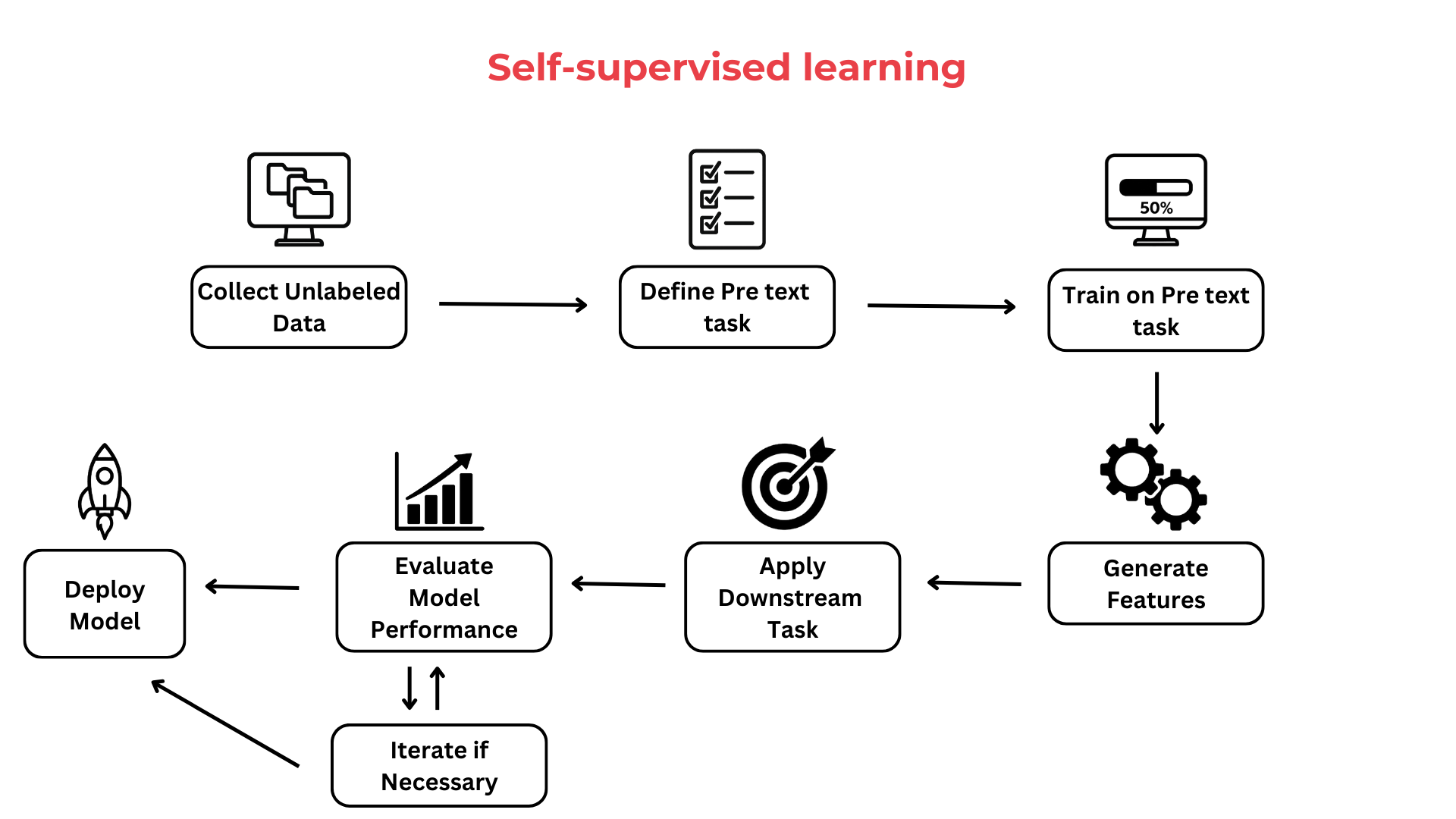
For vehicle damage detection, SSL enables us to pretrain models using unlabeled vehicle images, helping them learn visual patterns before introducing labeled examples.
Key Benefits:
- Reduces manual labeling effort
- Leverages large amounts of raw data
- Improves downstream performance on specific tasks like car damage detection
Popular SSL Models in Vision:
- DINO – Excels in segmentation and object detection
- BYOL – Learns features without negative samples
- SimCLR – Learns through contrastive learning using augmented images
- MoCo – Uses momentum contrast for more stable feature learning
- MAE – Reconstructs masked parts of an image (similar to MLM in NLP)
Why SSL Alone Isn’t Enough for Car Damage Detection
Despite its advantages, self-supervised learning presents key challenges in our use case:
- Damage Is a Minor FeatureMost images in our dataset prominently feature entire vehicles. The vehicle damage is often subtle, so SSL models tend to learn how to detect vehicles, not the actual damage.
- Subtle Patterns Are Hard to LearnDetecting small scratches or chips requires pixel-level understanding—something SSL models can struggle with due to their generalized learning process.
- Pretask LimitationsSSL models require pretext tasks like jigsaw solving or image rotation. These don’t always align with the goal of identifying car damage.
- Data fatigue will lead to wrong resultsFeeding too much unlabeled data without curation leads to poor results. Selective data input is crucial, which makes SSL resource-intensive in practice.
A Better Alternative: Semi-Supervised Learning
What Is Semi-Supervised Learning (Semi-SL)?
Semi-supervised learning bridges the gap between fully labeled and completely unlabeled data. It combines a small set of labeled images (e.g., bounding boxes showing vehicle damage) with a large set of unlabeled images to train the model efficiently.
Why We Prefer It for Damage Detection:
- More cost-effective than full labeling
- Uses existing bounding box (BBox) data efficiently
- Allows faster training and better generalization
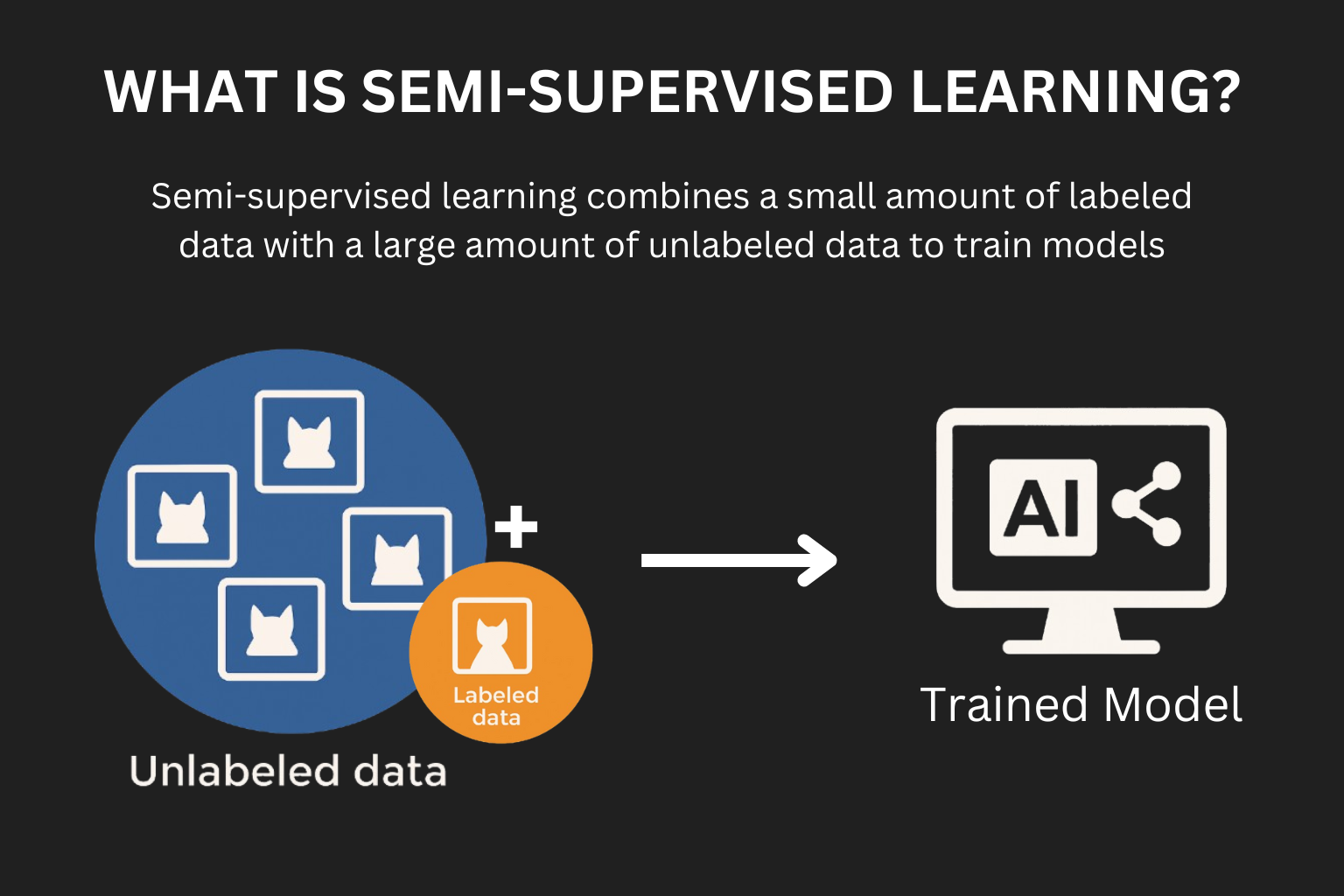
How We Use Semi-Supervised Learning for AI Car Damage Detection

Our semi-supervised training workflow includes:
- Training with Bounding Box DataBounding boxes are quicker to annotate and plentiful in our database. We start by using this data to detect general damage locations.
- Conversion to Segmentation DataWe convert BBox data into rectangular segmentation areas to improve precision.
- Fine-Tuning with Segmentation LabelsFinally, we fine-tune the model using actual segmentation data, helping it learn the exact shape and extent of the vehicle damage.
This hybrid method gives us the best of both worlds—speed and accuracy.
Conclusion
The evolution of AI car damage detection at Inspektlabs is powered by a thoughtful integration of emerging AI training methods.
While self-supervised learning helps us unlock the potential of unlabeled data, semi-supervised learning proves to be the most effective approach for detecting real-world vehicle damage.
By leveraging bounding box data and fine-tuning with segmentation, we’ve significantly improved our system’s performance, ensuring faster, more accurate, and cost-effective damage detection for vehicle inspections and insurance workflows.
As we continue to enhance our models, we remain committed to staying at the cutting edge of AI-powered vehicle damage detection.


